
|
시장보고서
상품코드
2064515
AI 트레이닝 데이터셋 시장 : 시장 점유율 분석, 산업 동향 및 통계 데이터, 성장 예측(2026-2031년)AI Training Dataset - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031) |
||||||
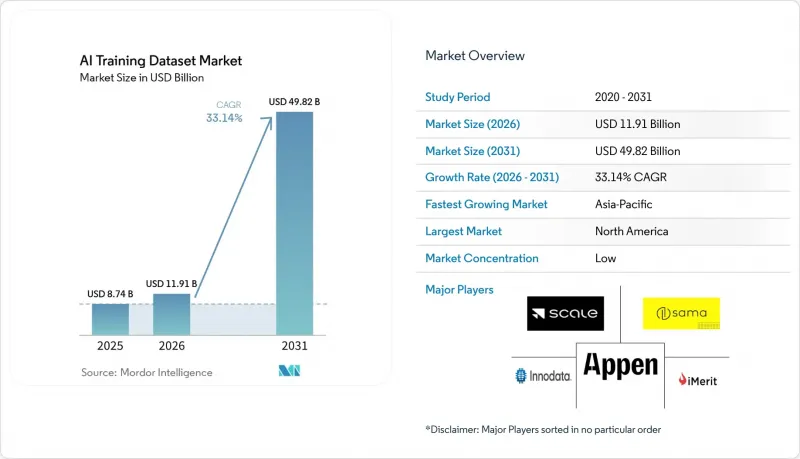
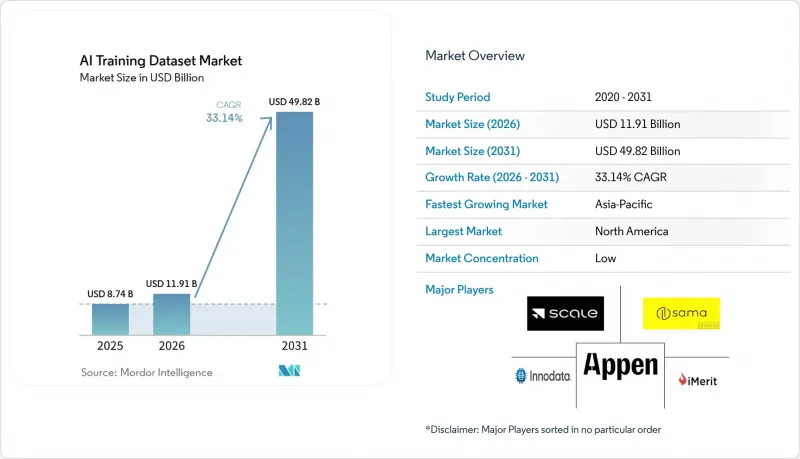
Mordor Intelligence에 의하면, AI 트레이닝 데이터셋 시장 규모는 2025년 87억 4,000만 달러로 평가되었고, 2026년에는 119억 1,000만 달러로 추정되고, 2026-2031년 CAGR 33.14%로 성장을 지속할 전망이며, 2031년에는 498억 2,000만 달러에 이를 것으로 예측됩니다.
본 보고서는 데이터 모달리티별(텍스트, 이미지·동영상, 음성·스피치 등), 데이터셋 제공 방식별(기성 데이터셋, 맞춤형 데이터셋 생성 등), 배포 방식별(온프레미스 등), 최종 사용자 산업별(IT 및 통신, 자동차·모달리티, 의료 및 생명과학, 은행, 금융서비스 및 보험(BFSI), 소매업·전자상거래 등), 지역별로 분류되어 있습니다. 시장 전망은 금액(달러) 기준으로 제시되어 있습니다.
세계의 AI 트레이닝 데이터셋 시장 동향 및 인사이트
다중 모달 LLM 및 생성형 AI 워크로드의 확대
다중 모달 대규모 언어 모델의 보급으로 인해, AI 트레이닝 데이터셋 시장에 대한 구매자들의 기대가 변화했습니다. 현재 서비스 제공업체는 단일 데이터 유형 내에서뿐만 아니라, 다양한 모달리티 간에도 의미를 유지하면서 동기화된 텍스트와 이미지 쌍, 시간축이 일치하는 동영상과 음성 시퀀싱, 그리고 기타 기록을 제공해야 합니다. 이에 따라 이미지 추론, 동영상 이해, 크로스모달 검색의 훈련과 평가를 모두 지원할 수 있는 데이터셋의 가치가 높아지고 있습니다. 이러한 확장성의 과제는 PDF, HTML, arXiv 자료를 결합하여 1조 200억 토큰 규모의 코퍼스로 확장한 오픈소스 멀티모달 데이터 ‘MINT-1T’의 출시에서 확인할 수 있습니다. 이와 유사한 요구 사항은 에이전트 기반 시스템에도 적용되고 있으며, 모델에는 정적 라벨뿐만 아니라 상호작용 기록, 작업 시연, 환경으로부터의 피드백이 필요합니다. 그 결과, 인공지능 훈련 데이터셋 시장에서는 기본적인 라벨링 작업보다 복잡한 어노테이션 및 크로스모달 품질 보증 분야에서 더 빠른 성장이 나타나고 있습니다.
규제 대상 워크플로우에서 도메인 특화형 데이터셋에 대한 수요 증가
규제 대상 워크플로우에서는 범용 코퍼스만으로는 부족하기 때문에 AI 트레이닝 데이터셋 시장이 활기를 띠고 있습니다. 의료, 법무, 금융 분야의 활용 사례에서는 익명화되고 추적 가능하며 자격을 갖춘 검토자가 라벨링한 데이터가 요구되고 있으며, 이로 인해 이미 관리된 환경에서 사업을 전개하고 있는 공급업체의 가치가 높아지고 있습니다. PhysioNet은 2025년, ER-REASON 등의 출시를 발표하며 이러한 추세를 더욱 확대했습니다. 이는 통제된 접근 조건 하에서 연구용 임상 추론 데이터셋에 대한 기관들의 지속적인 수요를 입증하는 것입니다. AI 개발자들이 중요한 용도를 뒷받침할 수 있는 주석이 달린 임상 기록, 의료 영상, 구조화된 기록이 필요하기 때문에 이것이 2031년까지 의료 분야에서 가장 빠르게 성장할 최종 사용자 부문인 이유 중 하나입니다. 비용 구조도 일반적인 데이터 업무와는 다릅니다. 이는 전문가의 검토, 익명화, 감사 문서화가 나중에 추가되는 것이 아니라 제공 프로세스에 통합되어 있기 때문입니다. 이를 통해 규제된 워크플로우에 통합된 공급업체의 이익률은 더욱 견고하게 유지되며, AI 트레이닝 데이터셋 시장에서 해당 분야에 대한 접근성이 지속적인 경쟁 우위로 작용할 것입니다.
데이터 개인정보 보호·주권·규정 준수 부담
개인정보 보호 및 규정 준수 관련 규정은 여전히 AI 트레이닝 데이터셋 시장에서 가장 구조적인 제약 요인으로 작용하고 있습니다. EU AI법은 2026년 8월 2일에 전면 시행되며, 고위험 AI 시스템에 대해 관련성이 있고 대표성을 갖추며 강력한 추적 가능성을 바탕으로 문서화된 데이터 세트의 사용을 의무화하고 있습니다. 이러한 의무는 GDPR(EU 개인정보보호규정)의 데이터 최소화 원칙과 상호 영향을 미치며, 훈련 코퍼스에 포함될 수 있는 개인정보의 양을 제한할 가능성이 있습니다. 이러한 상반된 요건으로 인해, 데이터가 실제 운영 환경에 이전되기 전에 공급업체는 현지화된 워크플로우, 보다 엄격한 문서화, 그리고 더 많은 법적 검토를 수행해야 하므로 프로젝트 비용이 증가합니다. 특히, 대표성과 개인정보 보호를 동시에 입증해야 하는 의료, 금융, 공공 부문에서의 도입에 있어서는 이것이 어렵습니다. AI 트레이닝 데이터셋 시장은 계속해서 성장할 것으로 예상되지만, 출처(데이터의 출처), 현지화 및 감사 가능성을 지원하지 못하는 공급업체는 대상 고객층이 좁아지게 될 것입니다.
부문별 분석
2025년, 텍스트 데이터는 AI 훈련 데이터 세트의 46.53%를 차지하며 가장 큰 모달리티가 되었습니다. 이러한 우위는 프론티어 및 엔터프라이즈 개발 프로그램 모두에서 대규모 언어 모델을 위한 사전 학습 코퍼스, 과제 특화형 미세 조정 데이터셋, 평가 자료에 대한 수요가 지속되고 있음을 반영합니다. LLM의 훈련 구조는 여전히 텍스트를 중시하고 있습니다. 왜냐하면 사전 훈련, 지도 학습을 통한 미세 조정, 정렬의 각 단계에서 각각 서로 다른 텍스트 자료가 필요하며, 각 단계마다 이전 단계보다 더 높은 품질 기준이 요구되기 때문입니다. 이에 따라 라이선스가 부여된 코퍼스, 전문적인 지침 세트, 다국어 자료 및 인간의 선호도 데이터에 대한 수요는 안정적으로 유지되고 있습니다. 2025년 NVIDIA가 출시한 ‘HelpSteer3-Preference’는 CC-BY-4.0 라이선스 하에 STEM, 코딩, 다국어 과제에 걸친 4만 쌍 이상의 인간이 주석을 달아 제공한 선호도 쌍을 통해 이러한 변화를 여실히 보여주었습니다. 실제로 이는 다른 모달리티가 부상하고 있음에도 불구하고, AI 트레이닝 데이터셋 시장이 모델 성능의 기반으로 여전히 텍스트에 의존하고 있음을 의미합니다.
음성 및 스피치 데이터는 음성 인터페이스, 다국어 인식, 자원이 제한된 언어에 대한 연구 분야에서 여전히 라벨이 지정된 음성 데이터나 파라언어적 특징이 필요하기 때문에 안정적인 수요를 유지하고 있습니다. 개발자가 단일 훈련 흐름 내에서 텍스트와 이미지, 음성, 구조화된 컨텍스트를 결합하는 사례가 늘어남에 따라, 멀티모달 데이터의 중요성이 커지고 있습니다. 동영상 데이터는 가장 빠르게 성장하고 있는 분야로, 2031년까지 연평균 성장률(CAGR)이 33.94%를 나타낼 것으로 전망됩니다. 이는 비전·언어 시스템 및 물리 AI 시스템을 위한 클립 수준의 정렬, 고밀도 캡션, 시계열 순서의 이벤트 처리에 의해 주도되고 있습니다. 동영상 데이터의 경우, 정지 화상 작업에 비해 공급 측면의 문제가 더 심각합니다. 왜냐하면 액션의 경계, 장면의 변화, 동기화된 지시 등 모든 것에 정확한 타이밍과 검토가 필요하기 때문입니다. MINT-1T는 경쟁력 있는 멀티모달 모델을 훈련하는 데 필요한 인프라의 규모를 입증했으며, 오픈소스 멀티모달 코퍼스를 기존 데이터셋보다 훨씬 더 많은 토큰 수로 확대했습니다. 그 결과, AI 트레이닝 데이터셋 업계는 텍스트가 여전히 기반을 이루고 있는 한편, 동영상이 고부가가치 주석 작업 수요의 주요 원동력이 되는 모델로 전환되고 있습니다.
2025년, AI 트레이닝 데이터셋 시장에서 기성 데이터셋은 46.84%를 차지했으며, 제공 형태와 관계없이 주도적인 위치를 유지했습니다. 구매자들은 고도의 맞춤화보다는 속도, 비용 관리, 표준적인 이용 사례가 중시되는 경우 이 모델을 선호하여 선택했습니다. 카탈로그 기반 조달은 일반적인 벤치마크나 광범위한 코퍼스로도 충분한 초기 모델 개발, 테스트 및 범용적인 훈련 작업에서 여전히 유용합니다. 이러한 장점은 마켓플레이스의 성숙에 따라 더욱 강화되고 있으며, 구조화된 메타데이터와 표준화된 라이선스 조건이 조달 과정의 마찰을 줄여주고 있습니다. 2025년에 도입된 AI 교육 컨텐츠용 라이선싱 체계(저작권 라이선스 기관(CLA)의 ‘Generative AI Training License’ 등)는 보다 체계화된 거래 모델로의 전환을 반영한 것입니다. 이를 통해 기업의 요구 사항이 더욱 구체화되어 가는 상황에서도, AI 트레이닝 데이터셋 시장은 대규모의 표준화된 공급 채널을 유지할 수 있게 됩니다.
맞춤형 데이터 세트 생성은 2031년까지 연평균 성장률(CAGR)이 33.74%에 달할 전망이며, 가장 빠르게 성장하고 있는 서비스입니다. 이는 규제 대상이며 특정 분야에 특화된 구매자들이, 카탈로그화 시스템에서는 거의 제공되지 않는 제품을 포괄하는 코퍼스를 필요로 하기 때문입니다. 의료, BFSI(은행 및 금융 및 보험), 정부 기관 및 기타 엄격한 심사를 받는 사용자들은 정의된 워크플로우에 부합하고, 출처 기록, 규정 준수 지원, 편향성 검토 기능이 포함된 맞춤형 데이터 세트를 필요로 합니다. 2025년 5월 뉴욕타임스가 아마존과 체결한, 뉴스룸 아카이브 및 관련 자산에 대한 AI 훈련용 접근 권한을 부여하는 라이선스 계약에서 알 수 있듯이, 저작권 처리가 완료된 컨텐츠도 이러한 변화의 한 축을 담당하고 있습니다. 이로 인해 AI 트레이닝 데이터셋 시장 내에서는 한쪽에는 대량 생산형 표준 제품이, 다른 한쪽에는 소량 생산이지만 높은 이익률을 기록하는 맞춤형 작업이 공존하는 더욱 양극화된 수익 구조가 형성되고 있습니다. 또한, 전문가의 주석 달기, 법적 검토, 감사 대응이 가능한 문서화를 단일 제공 모델로 통합할 수 있는 공급업체가 유리합니다. 따라서 AI 트레이닝 데이터셋 업계는 단일한 지배적인 조달 방식이 아닌, 보다 다층적인 상업 구조로 전환되고 있습니다.
지역별 분석
2025년, 북미는 AI 트레이닝 데이터셋 시장 점유율의 34.11%를 차지했습니다. 이는 최첨단 AI 연구소, 하이퍼스케일러의 인프라, 전문가에 의한 라벨링이 적용되고 저작권 처리가 완료된 데이터를 우선적으로 선택하는 기업 구매자들에 의해 주도된 현상입니다. 미국은 첨단 모델을 도입한 의료, 금융 서비스, 국방 분야의 고액 이용자를 보유하고 있어 수요를 주도하고 있습니다. Scale AI가 2025-2026년 사무실을 확장한 것은 주요 기업 AI 허브 인근으로 사업을 확장하는 공급업체들의 존재를 부각시켰습니다. 캐나다는 자율주행차 개발 및 이중 언어 지원 NLP(자연어 처리) 업무 분야에서 수요를 뒷받침하고 있으며, 멕시코는 미국 관련 라벨링 프로그램을 위해 비용 효율적인 인력을 제공합니다.
아시아태평양은 2031년까지 연평균 성장률(CAGR) 34.14%를 기록할 전망이며, 해당 시장에서 가장 높은 성장률을 보일 것으로 전망됩니다. 중국, 인도, 한국의 정부 주도의 AI 프로그램이 제조업, 의료, 스마트시티, 자율 시스템 분야 수요를 견인하고 있습니다. 인도는 대규모 주석 작성 인력 풀을 보유하고 있을 뿐만 아니라, 의료, 법무, 추론 데이터 분야에서 전문가 수준의 워크플로가 확대되고 있습니다. 중국은 민관 차원의 AI 투자를 통해 수요를 확대하고 있는 반면, 일본과 한국은 센서나 멀티모달 데이터가 필요한 자동차, 반도체, 정밀 제조 분야의 AI 프로그램에 주력하고 있습니다.
유럽의 AI 트레이닝 데이터셋 시장은 주석의 양보다는 규정 준수를 중심으로 한 조달에 의해 형성되고 있습니다. EU AI법 제10조는 고위험 용도를 대상으로 문서화되고, 감사 가능하며, 편향성이 검증된 데이터 세트를 개발할 것을 요구하고 있으며, 유럽의 전문 공급업체를 우대하고 있습니다. AI Verse가 2026년 1월에 조달한 500만 유로(530만 달러)의 자금은 규제 준수 요건이 강화되는 가운데 합성 컴퓨터 비전 데이터에 대한 관심이 반영된 결과입니다. 브라질을 필두로 한 남미에서는 현지 텍스트 데이터 및 지리 공간 데이터가 필요한 핀테크 및 애그리테크에 대한 수요가 증가하고 있습니다. 중동 및 아프리카는 아직 초기 단계에 있지만, 카타르, 사우디아라비아, UAE에서는 국내 데이터 확보 및 비정형 데이터 개발이 진행되고 있습니다.
기타 혜택 :
- Excel 형식 시장 예측(ME) 시트
- 3개월간의 애널리스트 지원
자주 묻는 질문
목차
제1장 서론
제2장 분석 방법
제3장 주요 요약
제4장 시장 구도
제5장 시장 규모 및 성장률 예측
제6장 경쟁 구도
제7장 시장 기회 및 향후 전망
AJYAccording to Mordor Intelligence, the aI training dataset market size is expected to grow from USD 8.74 billion in 2025 to USD 11.91 billion in 2026 and is forecast to reach USD 49.82 billion by 2031 at 33.14% CAGR over 2026-2031.
This report is Segmented by Data Modality (Text, Image and Video, Audio and Speech, and More), Dataset Offering (Off-The-Shelf Datasets, Custom Dataset Creation, and More), Deployment (On-Premises, and More), End-User Industry (IT and Telecom, Automotive and Modality, Healthcare and Life Sciences, BFSI, Retail and E-Commerce, and More), and Geography. The Market Forecasts are Provided in Terms of Value (USD).
Global AI Training Dataset Market Trends and Insights
Expansion of Multimodal LLMs and Generative AI Workloads
The spread of multimodal large language models has changed what buyers expect from the AI training dataset market. Providers now need to supply synchronized text-image pairs, time-aligned video-audio sequences, and other records that preserve meaning across modalities rather than within a single data type alone. This has raised the value of datasets that can support both training and evaluation for image reasoning, video understanding, and cross-modal retrieval. The scaling challenge is visible in the MINT-1T release, which expanded open-source multimodal data by combining PDFs, HTML, and arXiv material into a 1.02 trillion-token corpus. The same demand is carried into agentic systems, where models need interaction traces, task demonstrations, and environment feedback beyond static labels. As a result, the artificial intelligence training dataset market is seeing faster growth in complex annotation and cross-modal quality assurance than in basic labeling volume.
Rising Demand for Domain-Specific Datasets in Regulated Workflows
The AI training dataset market is gaining momentum as regulated workflows require general-purpose corpora that are not sufficient. Healthcare, legal, and financial use cases require data that is de-identified, traceable, and labeled by qualified reviewers, which increases the value of suppliers that already operate in controlled environments. PhysioNet expanded on that pattern in 2025 with releases such as ER-REASON, which demonstrated ongoing institutional demand for research-grade clinical reasoning datasets under governed access terms. This is one reason healthcare is the fastest-growing end-user segment through 2031, as AI developers need annotated clinical notes, medical imaging, and structured records that can support high-stakes applications. The cost profile is also different from general data work because expert review, de-identification, and audit documentation are built into delivery rather than added later. That keeps margins firmer for providers embedded in regulated workflows and makes domain access a durable advantage in the artificial intelligence training dataset market.
Data Privacy, Sovereignty, and Compliance Burdens
Privacy and compliance rules remain the most structural restraint on the AI training dataset market. The EU AI Act enters full enforcement on August 2, 2026, and requires high-risk AI systems to use datasets that are relevant, representative, and documented with strong traceability. Those obligations interact with GDPR data minimization rules, which can limit the amount of personal information that may be retained in training corpora. That tension increases project costs because providers need localized workflows, stronger documentation, and more legal review before data can move into production. It is especially difficult in healthcare, finance, and public-sector deployments, where representativeness and privacy must be demonstrated simultaneously. The AI training dataset market will continue to grow, but providers that cannot support provenance, localization, and auditability will face a narrower addressable customer base.
Other drivers and restraints analyzed in the detailed report include:
- Greater Use of Synthetic and Simulated Data
- Scaling of Physical AI and Autonomous Systems
- High Cost of Expert Annotation and Quality Assurance
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
Text data accounted for 46.53% of the AI training dataset in 2025, making it the largest modality. That lead reflected continued demand for pretraining corpora, instruction-tuning datasets, and evaluation material for large language models across both frontier and enterprise development programs. The structure of LLM training still favors text because pretraining, supervised fine-tuning, and alignment each require distinct text assets, and each step imposes higher quality thresholds than the one before. This has kept demand steady for licensed corpora, specialist instruction sets, multilingual material, and human preference data. NVIDIA's HelpSteer3-Preference release in 2025 illustrated that shift by providing more than 40,000 human-annotated preference pairs across STEM, coding, and multilingual tasks under a CC-BY-4.0 license. In practice, this means the AI training dataset market continues to rely on text as the foundation for model capabilities, even as other modalities gain ground.
Audio and speech data remain stable because voice interfaces, multilingual recognition, and low-resource language initiatives still require labeled speech and paralinguistic features. Multimodal data is gaining importance as developers increasingly combine text with image, audio, and structured context inside a single training flow. Video data is the fastest-growing modality, with a 33.94% CAGR through 2031, driven by clip-level alignment, dense captioning, and temporally ordered events for vision-language and physical AI systems. The supply challenge is more severe in video than in static-image work because action boundaries, scene changes, and synchronized instructions all require precise timing and review. MINT-1T demonstrated the scale of infrastructure needed to train competitive multimodal models, pushing open-source multimodal corpora to far larger token volumes than earlier datasets. As a result, the AI training dataset industry is moving toward a model in which text remains foundational, while video becomes the primary driver of higher-value annotation demand.
Off-the-shelf datasets accounted for 46.84% of the AI training dataset market in 2025, maintaining their leading position across offering types. Buyers favored this model when speed, cost control, and standard use cases mattered more than deep customization. Catalog-based procurement is still useful for early model development, testing, and generalized training tasks where common benchmarks and broad corpora are acceptable. That advantage is reinforced by the maturing marketplace layer, where structured metadata and standardized license terms reduce procurement friction. The launch of licensing structures for AI training content in 2025, including the Copyright Licensing Agency's Generative AI Training License, reflected the move toward more formalized exchange models. This helps the AI training dataset market maintain a large standardized supply channel even as enterprise requirements become more specific.
Custom dataset creation is the fastest-growing offering, with a 33.74% CAGR through 2031, because regulated and domain-heavy buyers need corpora that catalog products that are rarely provided by cataloging systems. Healthcare, BFSI, government, and other high-scrutiny users want bespoke datasets with documented provenance, compliance support, and bias review that can fit a defined workflow. Rights-cleared content is part of that shift, as shown by the New York Times licensing agreement with Amazon in May 2025 for AI training access to newsroom archives and affiliated properties. This creates a more split revenue structure inside the AI training dataset market, with high-volume standard products on one side and lower-volume, higher-margin custom work on the other. It also favors providers that can combine expert annotation, legal clearance, and audit-ready documentation within a single delivery model. The AI training dataset industry is therefore moving toward a more layered commercial structure rather than a single dominant procurement format.
Geography Analysis
North America accounted for 34.11% of the AI training dataset market share in 2025, driven by frontier AI labs, hyperscaler infrastructure, and enterprise buyers prioritizing expert-annotated, rights-cleared data. The U.S. leads demand with high-spend users in healthcare, financial services, and defense, deploying advanced models. Scale AI's 2025-2026 office expansion highlighted providers growing near major enterprise AI hubs. Canada supports demand with autonomous vehicle development and bilingual NLP work, while Mexico offers cost-efficient labor for U.S.-linked annotation programs.
Asia-Pacific is projected to grow at a 34.14% CAGR, the fastest in the market, through 2031. Government-backed AI programs in China, India, and South Korea drive demand across manufacturing, healthcare, smart cities, and autonomous systems. India combines a large annotation labor pool with growing expert-level workflows in medical, legal, and reasoning data. China boosts demand through public and private AI investments, while Japan and South Korea focus on automotive, semiconductor, and precision manufacturing AI programs requiring sensors and multimodal data.
Europe's AI training dataset market is shaped by compliance-driven procurement rather than annotation volume. The EU AI Act's Article 10 pushes developers toward documented, auditable, and bias-examined datasets for high-risk applications, favoring specialist European providers. AI Verse's EUR 5 million (USD 5.3 million) January 2026 funding reflects interest in synthetic computer vision data amid compliance needs. South America, led by Brazil, sees emerging demand for fintech and agritech that requires local text and geospatial data. The Middle East and Africa are at early stages, with Qatar, Saudi Arabia, and the UAE advancing domestic data procurement and the development of unstructured data.
- Scale AI, Inc.
- Appen Limited
- Samasource Impact Sourcing, Inc.
- iMerit Technology Services Private Limited
- Labelbox, Inc.
- SuperAnnotate AI, Inc.
- DefinedCrowd Corporation
- Dataloop Ltd.
- Kili Technology SAS
- Toloka AI B.V.
- Shaip
- Cogito Tech LLC
- Clickworker GmbH
- LXT AI, Inc.
- CloudFactory Limited
- NEXDATA TECHNOLOGY INC.
- Innodata Inc.
- Snorkel AI, Inc.
- Tonic.ai
- V7 Ltd.
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Expansion of Multimodal LLMs and Generative AI Workloads
- 4.2.2 Rising Demand for Domain-Specific Datasets in Regulated Workflows
- 4.2.3 Greater Use of Synthetic and Simulated Data
- 4.2.4 Scaling of Physical AI and Autonomous Systems
- 4.2.5 Shift Toward Post-Training Preference, Agent Trajectory, and Evaluation Data
- 4.2.6 Growth of Rights-Cleared Licensed Content Markets
- 4.3 Market Restraints
- 4.3.1 Data Privacy, Sovereignty, and Compliance Burdens
- 4.3.2 High Cost of Expert Annotation and Quality Assurance
- 4.3.3 Training-Data Contamination from AI-Generated Web Content
- 4.3.4 Fragmented Licensing Provenance and Chain-of-Custody Requirements
- 4.4 Impact of Macroeconomic Factors on the Market
- 4.5 Industry Value Chain Analysis
- 4.6 Regulatory Landscape
- 4.7 Technological Outlook
- 4.8 Porter's Five Forces Analysis
- 4.8.1 Bargaining Power of Suppliers
- 4.8.2 Bargaining Power of Buyers
- 4.8.3 Threat of New Entrants
- 4.8.4 Threat of Substitutes
- 4.8.5 Intensity of Competitive Rivalry
5 MARKET SIZE AND GROWTH FORECASTS (VALUE)
- 5.1 By Data Modality
- 5.1.1 Text
- 5.1.2 Image and Video
- 5.1.3 Audio and Speech
- 5.1.4 Multimodal and Sensor-Rich Data
- 5.2 By Dataset Offering
- 5.2.1 Off-the-Shelf Datasets
- 5.2.2 Custom Dataset Creation
- 5.2.3 Dataset Marketplaces and Licensed Exchanges
- 5.3 By Deployment Model
- 5.3.1 On-premises
- 5.3.2 Cloud
- 5.3.3 Hybrid
- 5.4 By End-User Industry
- 5.4.1 IT and Telecom
- 5.4.2 Automotive and Mobility
- 5.4.3 Healthcare and Life Sciences
- 5.4.4 BFSI
- 5.4.5 Retail and E-commerce
- 5.4.6 Government and Defense
- 5.4.7 Media and Entertainment
- 5.4.8 Manufacturing and Industrial
- 5.5 By Geography
- 5.5.1 North America
- 5.5.1.1 United States
- 5.5.1.2 Canada
- 5.5.1.3 Mexico
- 5.5.2 South America
- 5.5.2.1 Brazil
- 5.5.2.2 Argentina
- 5.5.2.3 Rest of South America
- 5.5.3 Europe
- 5.5.3.1 United Kingdom
- 5.5.3.2 Germany
- 5.5.3.3 France
- 5.5.3.4 Italy
- 5.5.3.5 Spain
- 5.5.3.6 Rest of Europe
- 5.5.4 Asia-Pacific
- 5.5.4.1 China
- 5.5.4.2 Japan
- 5.5.4.3 India
- 5.5.4.4 South Korea
- 5.5.4.5 Rest of Asia-Pacific
- 5.5.5 Middle East and Africa
- 5.5.5.1 Middle East
- 5.5.5.1.1 United Arab Emirates
- 5.5.5.1.2 Saudi Arabia
- 5.5.5.1.3 Rest of Middle East
- 5.5.5.2 Africa
- 5.5.5.2.1 South Africa
- 5.5.5.2.2 Egypt
- 5.5.5.2.3 Rest of Africa
- 5.5.5.1 Middle East
- 5.5.1 North America
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Strategic Moves
- 6.3 Market Share Analysis
- 6.4 Company Profiles (includes Global Level Overview, Market Level Overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share, Products and Services, Recent Developments)
- 6.4.1 Scale AI, Inc.
- 6.4.2 Appen Limited
- 6.4.3 Samasource Impact Sourcing, Inc.
- 6.4.4 iMerit Technology Services Private Limited
- 6.4.5 Labelbox, Inc.
- 6.4.6 SuperAnnotate AI, Inc.
- 6.4.7 DefinedCrowd Corporation
- 6.4.8 Dataloop Ltd.
- 6.4.9 Kili Technology SAS
- 6.4.10 Toloka AI B.V.
- 6.4.11 Shaip
- 6.4.12 Cogito Tech LLC
- 6.4.13 Clickworker GmbH
- 6.4.14 LXT AI, Inc.
- 6.4.15 CloudFactory Limited
- 6.4.16 NEXDATA TECHNOLOGY INC.
- 6.4.17 Innodata Inc.
- 6.4.18 Snorkel AI, Inc.
- 6.4.19 Tonic.ai
- 6.4.20 V7 Ltd.
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment
