





|
시장보고서
상품코드
1815981
휴머노이드 로봇 세계 전략 : 동서 모델 경쟁 분석(2025년)Humanoid Robots Global Strategies: East-West Model Race Analysis 2025 |
||||||
현재 휴머노이드 로봇의 발전은 시각-언어-행동(VLA) 모델의 최적화, 멀티모달 데이터 통합, 인간의 의도를 해석하는 능력뿐만 아니라 지시 이해 능력의 강화가 중심이 되고 있습니다. 훈련은 세계 모델, 인간 비디오 데이터, VR 기반 원격 훈련에 크게 의존하고, 인식을 강화하기 위해 1 인칭 시점에 점점 더 중점을 둡니다. 최종 목표는 범용 휴머노이드의 실현이지만, 개발은 여전히 큰 과제에 의해 제약을 받고 있으며, 유럽과 미국 기업과 중국 기업은 각각 다른 기술 경로를 추구하고 있습니다.
샘플
주요 하이라이트
- 휴머노이드 로봇은 시각-언어-행동(VLA) 모델 최적화와 멀티모달 데이터 통합 강화에 중점을 두고 있습니다.
- 지시 이해와 인간의 의도 해석의 개선은 핵심 개발 분야입니다.
- 훈련은 세계 모델, 인간 비디오 데이터, VR 기반 원격 훈련에 크게 의존하고 있으며, 1인칭 시점에 중점을 두고 있습니다.
- 최종 목표는 범용 휴머노이드의 실현이지만, 기술적으로 큰 과제가 남아있습니다.
- 유럽과 미국, 중국 기업은 이에 대해 서로 다른 기술적 경로를 추구하고 있습니다.
목차
제1장 로봇 지각의 핵심이 되는 시각 모델
제2장 휴머노이드 로봇 모델 개발자의 전략적 동향
제3장 TRII의 견해
KSA 25.09.26Current progress in humanoid robotics is centered on optimizing vision-language-action (VLA) models, integrating multimodal data, and enhancing instruction comprehension as well as the ability to interpret human intent. Training relies heavily on world models, human video data, and VR-based remote training, with increasing emphasis on first-person perspectives to strengthen perception. While the ultimate goal is to achieve general-purpose humanoids, development remains constrained by significant challenges, leading Western and Chinese companies to pursue divergent technological pathways.
SAMPLE VIEW
Key Highlights:
- Humanoid robotics focuses on optimizing vision-language-action (VLA) models and enhancing multimodal data integration.
- Improving instruction comprehension and human intent interpretation is a core development area.
- Training relies heavily on world models, human video data, and VR-based remote training, with growing emphasis on first-person perspectives.
- The ultimate goal is to achieve general-purpose humanoids, but major technical challenges persist.
- Western and Chinese companies are pursuing different technological pathways in response.
Table of Contents
1. Vision Models as the Core of Robotic Perception
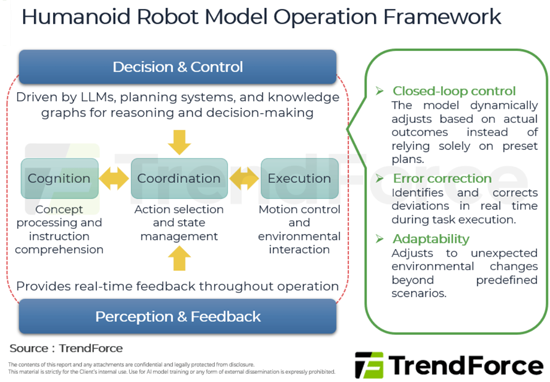
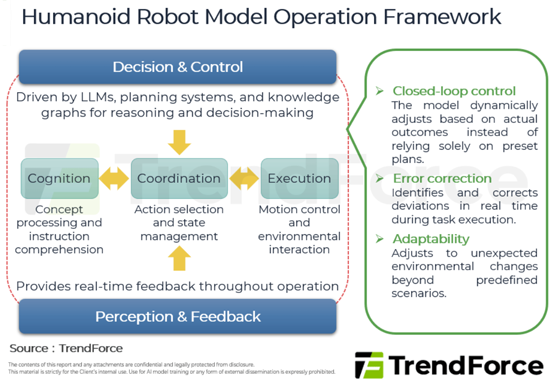
- Figure 1: Humanoid Robot Model Operation Framework
- Figure 2: Training Data for Humanoid Robots
- Table 1: Comparison of First-Person and Third-Person View Algorithms
- Figure 3: Apple HAT Model Overview
- Table 2: Summary of First-Person Datasets
2. Strategic Moves by Humanoid Robot Model Developers
- Figure 4: ViLLA Architecture









