
|
시장보고서
상품코드
2063916
오믹스 분야 AI 시장 : 시장 점유율 분석, 업계 동향 및 통계, 성장 예측(2026-2031년)AI In Omics - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031) |
||||||
Mordor Intelligence에 의하면, 오믹스 분야 AI 시장 규모는 2025년에 12억 1,000만 달러로 평가되었고, 2026년 16억 1,000만 달러로 추정되고, 2031년까지 51억 4,000만 달러에 이를 것으로 예측되며, 예측 기간(2026-2031년) CAGR은 26.09%를 나타낼 전망입니다.
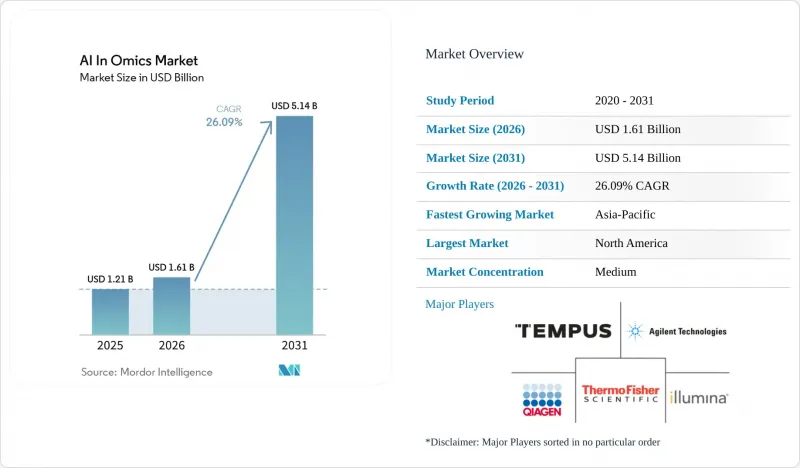
본 보고서는 구성 요소별(소프트웨어, 하드웨어, 서비스), 오믹스 유형별(유전체학, 전사체학, 단백체학, 기타), AI 기술별(머신러닝, 딥러닝, 자연어 처리, 컴퓨터 비전, 데이터 마이닝), 용도별(임상 진단, 기타), 최종 사용자별(제약 및 바이오기술 기업, 기타), 지역별(북미, 유럽, 아시아태평양, 중동 및 아프리카, 남미)로 분류되어 있습니다. 시장 전망은 금액(달러) 기준으로 제시되어 있습니다.
세계의 오믹스 분야 AI 시장 동향 및 인사이트
정밀 의학의 도입이 의약품 개발의 경제성을 재편하고 있습니다.
정밀 종양학 및 희귀질환의 워크플로우에 따라 분자 프로파일링이 치료법 선택에서 더욱 핵심적인 위치를 차지하게 되었으며, 이에 따라 임상 팀이 오믹스 분야 AI 시장에서 시간, 자본, 임상 검사 자원을 어디에 투입할지 결정하는 방식이 변화하고 있습니다. 이러한 변화는 중요한 의미를 지닙니다. 왜냐하면, 멀티오믹스 모델은 환자 집단을 더 조기에 선별하는 데 도움이 되며, 생물학적 신호, 검사 설계, 그리고 이후의 치료 반응 간의 일관성을 높일 수 있기 때문입니다. Tempus AI의 Lens 플랫폼에 따르면, 이 모델은 상업적으로 확대되고 있으며, 데이터 및 용도 매출은 2025년에 3억 1,640만 달러에 달하고, 전년 대비 30.9% 증가할 것으로 전망됩니다. 또한 Tempus는 2025년 총매출이 13억 달러에 달할 것이라고 보고했는데, 이는 AI 관련 임상 및 데이터 서비스가 단발성 시범 사업에서 재현 가능한 운영 모델로 전환되고 있음을 보여줍니다. 이러한 워크플로가 개발의 초기 단계로 넘어감에 따라, 질환 특이적 채널에 대한 인사이트를 관련 프로그램 간에 재사용할 수 있게 되어, 각 큐레이션된 데이터 세트의 상업적 수익성이 향상됩니다. 이를 통해 오믹스 분야 AI 시장은 신약 개발 그룹, 중개 연구자, 임상 분야에 중점을 둔 소프트웨어 공급업체로부터 동시에 투자를 유치하는 데 성공하고 있습니다.
증가하는 오믹스 데이터 양이 기존 분석 인프라에 부담을 주고 있습니다.
데이터 양 증가는 오믹스 분야 AI 시장을 이끄는 핵심 성장 동력으로 자리 잡고 있습니다. 왜냐하면, 다층적인 생물학적 데이터 세트는 많은 기존 분석 스택에 비해 너무 방대하고 복잡해졌기 때문입니다. 현대 프로젝트에서는 단일 모달리티만을 단독으로 다루는 경우는 거의 없으며, 시퀀싱, 발현, 단백질, 표현형, 임상적 맥락을 동일한 계산 환경 내에서 함께 처리해야 하는 경우가 많습니다. 이로 인해 스토리지뿐만 아니라 전처리, 데이터 통합, 추론 속도, 검증 추적, 그리고 새로운 데이터가 지속적으로 유입되는 상황에서의 재학습 능력에도 부하가 가해지고 있습니다. NVIDIA는 Parabricks가 CPU 워크플로우에 비해 50% 낮은 계산 비용으로 전체 유전체 분석을 100배 이상 가속화할 수 있다고 밝혔으며, 이것이 가속화 및 클라우드 지원 파이프라인이 지지를 얻고 있는 이유를 보여줍니다. 일단 그 스택을 채택하면, 데이터 모델, 검증 루틴, 사용자의 습관이 플랫폼 아키텍처에 얽매이게 되므로 마이그레이션이 어려워집니다. 이것이 바로 오믹스 시장의 AI가 독립형 도구에서 계산, 분석, 워크플로 관리를 단일 계층으로 통합한 환경으로 전환되고 있는 이유입니다.
데이터 개인정보 보호 및 동의와 관련된 제약 사항으로 인해 훈련 데이터 세트가 세분화되고 있습니다.
데이터 개인정보 보호 및 동의 관련 규정에 따라, 오믹스 시장의 AI는 해당 기록의 과학적 가치가 높더라도 생성된 데이터를 모두 활용할 수 없습니다. 전체 유전체 염기서열은 다른 많은 임상 기록만큼 쉽게 익명화할 수 없기 때문에 기관들은 여전히 접근, 저장, 연계, 2차 이용과 관련된 엄격한 거버넌스 요건에 직면해 있습니다. 유럽연합 집행위원회에 따르면, 2026년 3월에 발효된 EHDS 규정은 유전체, 프로테옴, 트랜스크립토믹스, 대사체, 후성유전체 데이터의 2차 이용을 규정하고 있으나, 각국의 건강 데이터 접근 기관이 본격적으로 가동되기까지는 앞으로 몇 년이 더 걸릴 전망입니다. 즉, 단기적으로는 접속 상황에 편차가 남아 있으며, 지역에 따른 동의 규정, 법적 심사, 보안 요건 등이 여전히 여러 기관에 걸친 데이터 세트 구축을 지연시키고 있습니다. 접근이 가장 어려운 데이터에는 종종 과소평가된 조상 집단이 포함되어 있으며, 모델이 더 좁고 대표성이 낮은 코호트를 통해 학습될 경우 편향이 심화될 가능성이 있습니다. 연방 학습은 오믹스 분야 AI 시장에서 중앙 집중식 데이터 전송을 줄이는 데 도움이 되지만, 그럼에도 불구하고 공동 거버넌스, 호환 가능한 워크플로우, 기관 간 확실한 협력에 의존하고 있습니다.
부문별 분석
소프트웨어는 2025년 매출의 55.2%를 차지했으며, 오믹스 분야 AI 시장에서 가장 큰 비중을 차지하는 부문으로서의 위상을 유지하는 한편, 플랫폼 주도의 상용화가 지닌 강점을 반영했습니다. 이러한 우위는 사전에 구축된 파이프라인, 선별된 지식 레이어, 컴퓨팅 접근성, 시각화 도구를 오믹스 분석용 단일 운영 체제에 통합한 클라우드 기반 환경을 통해 실현되었습니다. 많은 사용자에게 있어, 이를 통해 멀티오믹스 작업을 시작하기 전에 사내 인프라를 구축해야 할 필요성이 줄어들며, 데이터를 보유하고 있지만 엔지니어링 역량이 제한적인 팀도 쉽게 도입할 수 있게 됩니다. 또한, 애널리스트가 여러 도구를 조합할 필요 없이 단일 워크플로우 내에서 원시 데이터에서 해석 단계로 바로 넘어갈 수 있으므로, 사용을 시작하는 데 걸리는 시간도 단축됩니다. 하드웨어가 여전히 최소한의 구성 요소로만 남아 있는 이유는 현재 더 많은 분석 워크로드가 로컬 장비에서 분리되어 확장 가능한 원격 환경으로 이전되고 있기 때문입니다.
서비스 부문은 2031년까지 연평균 성장률(CAGR) 34.9%를 나타낼 것으로 예측되며, 이는 오믹스 AI 시장 규모 내에서 가장 빠르게 확대되고 있는 부문임을 보여줄 뿐만 아니라, 부가가치 창출이 어떤 방향으로 나아가고 있는지를 시사합니다. 기관 및 이용 사례를 아우르며 프로젝트를 표준화하기가 점점 더 어려워짐에 따라, 수요는 맞춤형 모델 개발, 생물정보학 컨설팅, 워크플로우 관리, 장기적인 데이터 통합 지원으로 이동하고 있습니다. QIAGEN은 자사의 Digital Insights 사업부가 2025 회계연도에 환율 변동의 영향을 제외한 두 자릿수 성장을 달성했다고 밝히며, 2028년까지 최소 14개의 AI 기반 용도를 제공할 계획이라고 발표했습니다. 이 점은 중요합니다. 왜냐하면 오믹스 분야 AI 산업은 소프트웨어 코어를 중심으로 지속적인 서비스 수요를 창출하고 있으며, 특히 초기 도입 후 사용자가 검증, 재훈련, 규제 관련 문서 작성, 워크플로우 조정이 필요한 상황에서 그 효과가 두드러지기 때문입니다. AI 도구가 규제 대상이나 임상 관련 환경에 깊이 침투함에 따라, 외부 지원은 단순한 선택 사항이 아니라 일상적인 운영 모델에 없어서는 안 될 요소가 되어가고 있습니다.
유전체학 시장은 2025년에 매출의 35.2%를 차지한 것으로 평가되었으며, 2031년까지 연평균 성장률(CAGR) 40.1%로 성장할 것으로 전망됩니다. 이는 오믹스 분야 AI 시장에서 유전체학이 규모와 성장 양면에서 주도적인 위치를 차지하고 있음을 의미합니다. 이 위치는 유전체 서열이 하류의 발현, 단백질, 표현형 신호를 연결하는 출발점 역할을 하는 경우가 많기 때문에 대부분의 멀티오믹스 워크플로우에서 기반 계층으로서의 역할을 반영하고 있습니다. 집단 시퀀싱 및 바이오뱅크와 연계된 연구의 확산에 따라, 모델 개발에 활용할 수 있는 훈련 데이터 기반은 지속적으로 확대되고 있으며, 이로 인해 유전체학은 상업적으로 가장 핵심적인 오믹스 분야로서 확고한 위치를 차지하고 있습니다. 트랜스크립토믹스와 단백질체학는 임상 및 신약 개발 현장에서 시퀀싱 데이터만으로는 얻을 수 없는 기능적 맥락을 보완함으로써, 상호 보완적인 영역으로서 그 존재감을 높여가고 있습니다. 대사체학과 후성유전체학은 수익 규모 면에서는 여전히 작지만, 염기서열의 변화만으로는 완전히 파악할 수 없는 표현형의 변동을 설명하는 데 도움이 되기 때문에 이에 대한 연구 관심은 계속해서 높아지고 있습니다.
옴릭스 분야의 AI 시장은 여전히 유전체학을 중심으로 하고 있습니다. 왜냐하면 새로운 멀티모달 모델은 대개 시퀀싱 데이터에서 시작하여, 컨텍스트가 확장됨에 따라 다른 생물학적 계층을 추가해 나가기 때문입니다. NVIDIA에 따르면, Evo 2는 12만 8,000개 이상의 유전체에서 추출한 8조 8,500억 염기쌍을 활용해 학습된, 400억 개의 매개변수를 가진 유전체 기반 모델입니다. 이러한 규모는 유전체 서열이 향후 트랜스크립토믹스, 프로테옴, 임상적 맥락을 포괄할 수 있는 더 대규모의 생물학적 기반 모델의 주요 토대가 되고 있다는 관점을 뒷받침하고 있습니다. 옴릭스 분야의 AI 산업에서 이에 따라 유전체학은 밸류체인 전반에 걸친 제품 설계, 장기적인 모델 학습, 라이선싱의 우선순위 중심에 계속해서 자리 잡고 있습니다. 또한, 이는 보다 광범위한 멀티오믹스 플랫폼이 지속적으로 발전해 나가는 가운데, 이미 고품질의 유전체 워크플로우를 숙지하고 있는 공급업체가 중요한 선점 우위를 유지하고 있음을 의미합니다.
지역별 분석
2025년, 북미는 오믹스 분야 AI 시장의 38.2%를 차지했으며, 지역별 최대 수익원이 되었습니다. 이는 시퀀싱 인프라, AI 인재, 제약 연구비가 단일 생태계에 집중되어 있음을 반영합니다. 미국이 이러한 주도적 위치를 차지하고 있는 것은 임상 유전체학 네트워크, 데이터 중심 소프트웨어 기업, 대학 병원, 대형 제약 개발 기업들이 이미 긴밀하게 협력하고 있기 때문입니다. Tempus의 보고서에 따르면, 2025년 매출액은 전년 대비 83.4% 증가한 13억 달러를 기록했습니다. 이는 임상 데이터, 분석 기술, 보험사 측의 이해가 일치할 때 미국의 환경이 뒷받침할 수 있는 상용화 규모를 보여줍니다. 미국 식품의약국(FDA)이 2025년에 내린 동반 진단에 관한 결정 역시, 근거 자료가 충실하다면 AI 연계형 분자 검사가 명확한 규제 절차를 통과할 수 있음을 보여주었습니다. 이러한 인프라의 충실도, 상환 제도에 대한 이해, 규제 대응 경험이 어우러져 북미는 오믹스 분야 AI 시장 도입 속도 면에서 우위를 점하고 있습니다.
유럽은 정책 구조가 장기적인 데이터 활용을 가능하게 하는 한편, 많은 참여자들에게 단기적인 규정 준수 비용을 증가시키고 있음에도 불구하고, 오믹스 분야 AI 시장에서 여전히 주요 지역으로 자리 잡고 있습니다. 유럽연합 집행위원회에 따르면, EHDS 규정은 2026년 3월에 발효되며, 유전체, 프로테옴, 트랜스크립톰, 대사체, 후성유전체 데이터의 2차 이용을 대상으로 합니다. 독일의 genomDE 모델 프로젝트는 2024년 가을까지 5,000명 이상의 환자 데이터를 통합했으며, 5년 내에 10만 건의 전체 유전체 염기서열을 수집하는 것을 목표로 하고 있습니다. 이러한 프로그램 덕분에 해당 지역의 이용 가능한 데이터베이스는 앞으로 확대될 전망이지만, EU AI법과 관련된 거버넌스 조치로 인한 운영상의 부담은 여전히 기존 공급업체에 유리하게 작용하고 있습니다.
아시아태평양은 연평균 성장률(CAGR) 37.4%를 나타낼 것으로 예측되며, 2031년까지 오믹스 분야 AI 시장 규모 측면에서 가장 급속한 지역적 확장을 이룰 것으로 전망됩니다. 이는 정부 주도의 유전체학 및 디지털 헬스 프로그램의 추진력이 강화되고 있음을 시사합니다. 이러한 추세는 주요 아시아 국가들이 현지 시퀀싱 역량 구축, 임상 데이터 시스템 강화, 서유럽 중심의 훈련 데이터 세트에 대한 의존도 저감에 힘쓰고 있음을 반영합니다. 일본에서도 언어 모델을 유전체학 분야에 적극적으로 적용하려는 움직임이 나타나고 있으며, DBCLS는 2026년에 ChatTogoVar가 유전체 변이 해석에서 GPT-4o를 능가하는 성능을 보였습니다고 보고했습니다. 남미, 중동 및 아프리카는 현재로서는 시장 규모가 작지만, 헬스케어 인프라 구축과 스타트업 활동의 활성화에 힘입어 향후 도입 기회가 점차 확대될 것으로 전망됩니다.
기타 혜택
- 엑셀 형식 시장 예측(ME) 시트
- 3개월간의 애널리스트 지원
자주 묻는 질문
목차
제1장 서론
제2장 조사 방법
제3장 주요 요약
제4장 시장 구도
제5장 시장 규모 및 성장 예측
제6장 경쟁 구도
제7장 시장 기회 및 향후 전망
AJYAccording to Mordor Intelligence, the aI in omics market size was valued at USD 1.21 billion in 2025 and is estimated to grow from USD 1.61 billion in 2026 to reach USD 5.14 billion by 2031, at a CAGR of 26.09% during the forecast period (2026-2031).
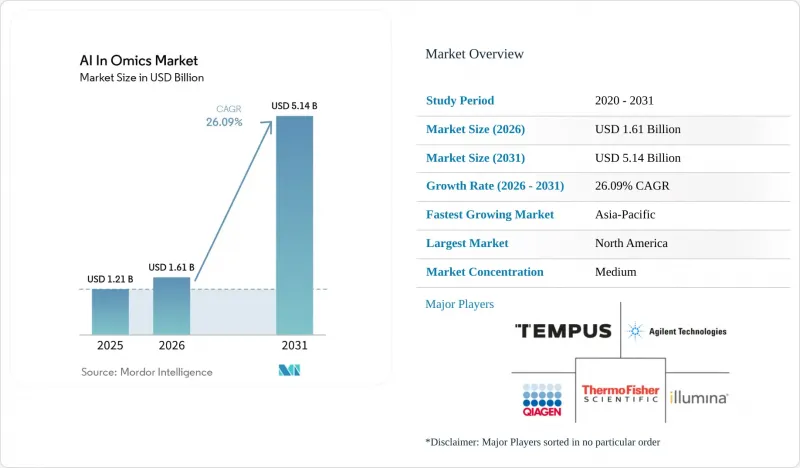
This report is Segmented by Component (Software, Hardware, Services), Omics Type (Genomics, Transcriptomics, Proteomics, and More), AI Technology (ML, Deep Learning, NLP, CV, Data Mining), Application (Clinical Diagnostics, and More), End User (Pharmaceutical Companies, and More), and Geography (North America, Europe, Asia-Pacific, MEA, South America). The Market Forecasts are Provided in Terms of Value (USD).
Global AI In Omics Market Trends and Insights
Precision Medicine Adoption Reshaping Drug Development Economics
Precision oncology and rare disease workflows are moving molecular profiling closer to the center of therapeutic selection, which is changing how clinical teams decide where to place time, capital, and trial resources in the AI in omics market. That shift matters because multi-omics models can help narrow patient groups earlier, which supports better alignment between biological signal, trial design, and downstream treatment response. Tempus AI's Lens platform shows that this model is scaling commercially, with Data and Applications revenue reaching USD 316.4 million in 2025, up 30.9% year over year. Tempus also reported total 2025 revenue of USD 1.3 billion, which indicates that AI-linked clinical and data services are moving beyond isolated pilot work and into repeatable operating models. As these workflows move earlier in development, disease-specific pathway findings can be reused across related programs, which improves the commercial return on each curated dataset. That is helping the AI in omics market attract spending from drug discovery groups, translational researchers, and clinically focused software vendors at the same time.
Rising Omics Data Volumes Straining Legacy Analytical Infrastructure
Rising data volumes remain a basic growth engine for the AI in omics market because multi-layer biological datasets are becoming too large and too complex for many legacy analytical stacks. Modern projects rarely work with one modality in isolation, so sequence, expression, protein, phenotype, and clinical context often need to be processed together inside the same computational environment. That creates pressure not just on storage, but also on preprocessing, harmonization, inference speed, validation tracking, and retraining capacity as new records continue to arrive. NVIDIA states that Parabricks can deliver more than 100 times faster whole-genome analysis at 50% lower compute cost than CPU workflows, which shows why accelerated and cloud-ready pipelines are gaining favor. Once an institution commits to that stack, migration becomes harder because data models, validation routines, and user habits become tied to the platform architecture. This is why the AI in omics market is moving away from stand-alone tools and toward integrated environments that combine compute, analytics, and workflow management in a single layer.
Data Privacy and Consent Constraints Fragmenting Training Datasets
Data privacy and consent rules keep the AI in omics market from using all of the data it generates, even when the scientific value of those records is high. Whole-genome sequences cannot be de-identified as easily as many other clinical records, so institutions still face strict governance expectations around access, storage, linkage, and secondary use. The European Commission states that the EHDS Regulation entered into force in March 2026 and covers secondary use of genomic, proteomic, transcriptomic, metabolomic, and epigenomic data, but national Health Data Access Bodies will only become operational over time. That means near-term access remains uneven, with local consent rules, legal reviews, and security requirements still slowing multi-site dataset assembly. The hardest-to-access material often includes underrepresented ancestry groups, which can deepen bias when models are trained on narrower and less representative cohorts. Federated learning can help the AI in omics market reduce central data transfer, but it still depends on shared governance, compatible workflows, and reliable coordination across institutions.
Other drivers and restraints analyzed in the detailed report include:
- AI Compressing the Biomarker-to-Clinical-Trial Pipeline
- Companion Diagnostics Embedding AI Omics Into Regulatory Workflows
- Multiomics Data Standardization Constraining Cross-Platform Interoperability
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
Software accounted for 55.2% of 2025 revenue, which kept it as the largest component in the AI in omics market and reflected the strength of platform-led commercialization. That lead came from cloud-based environments that combine prebuilt pipelines, curated knowledge layers, compute access, and visualization tools into one operating system for omics analysis. For many users, this reduces the need to build internal infrastructure before beginning multi-omics work, which makes adoption easier for teams that have data but limited engineering capacity. It also shortens time to use because analysts can move from raw files to interpretation inside a single workflow instead of stitching together multiple tools. Hardware remained the smallest component because more analytical workloads are now being separated from local instrumentation and shifted into scalable remote environments.
Services are projected to grow at 34.9% CAGR through 2031, which makes them the fastest-expanding component of the AI in omics market size and shows where incremental value creation is moving. Demand is shifting toward custom model development, bioinformatics consulting, workflow management, and long-cycle data integration support as projects become harder to standardize across institutions and use cases. QIAGEN said its Digital Insights business delivered double-digit constant-exchange-rate growth in FY2025 and that the company plans at least 14 AI-enabled applications by 2028. That matters because the AI in omics industry is creating recurring service demand around software cores, especially where users need validation, retraining, regulatory documentation, and workflow tuning after initial deployment. As AI tools move deeper into regulated and clinically linked settings, external support becomes less optional and more embedded in the day-to-day operating model.
Genomics held 35.2% of revenue in 2025 and is forecast to expand at 40.1% CAGR through 2031, which means it leads both scale and growth in the AI in omics market. That position reflects its role as the base layer for most multi-omics workflows, since genomic sequence often serves as the starting frame for linking downstream expression, protein, and phenotype signals. Population-scale sequencing and the wider use of biobank-linked research continue to enlarge the training base available for model development, which reinforces genomics as the most commercially central omics layer. Transcriptomics and proteomics are gaining ground as complementary layers because they add functional context that sequence data alone cannot provide in clinical and drug development settings. Metabolomics and epigenomics remain smaller in revenue, but research interest keeps rising because both layers help explain phenotypic variability that sequence changes do not fully capture on their own.
The AI in omics market still centers on genomics because new multimodal models usually begin with sequence data and then attach other biological layers as the context widens. NVIDIA said Evo 2 is a 40-billion parameter genomic foundation model trained on 8.85 trillion nucleotides from more than 128,000 genomes. That scale supports the view that genomic sequence is becoming the primary substrate for larger biological foundation models that can later absorb transcriptomic, proteomic, and clinical context. Within the AI in omics industry, this keeps genomics at the center of product design, long-horizon model training, and data licensing priorities across the value chain. It also means suppliers that already control high-quality genomic workflows hold an important starting advantage as broader multi-omics platforms continue to evolve.
Geography Analysis
North America held 38.2% of the AI in omics market share in 2025, which made it the largest regional revenue pool and reflected the concentration of sequencing infrastructure, AI talent, and pharmaceutical research spending in one ecosystem. The United States drives that lead because clinical genomics networks, data-oriented software firms, academic medical centers, and large drug developers are already deeply connected. Tempus reported USD 1.3 billion in 2025 revenue, up 83.4% year over year, which illustrates the commercialization scale that the U.S. environment can support when clinical data, analytics, and payer familiarity line up. The U.S. Food and Drug Administration's 2025 companion diagnostic decisions also showed that AI-linked molecular tests can move through recognizable regulatory paths when evidence packages are strong. That combination of infrastructure depth, reimbursement familiarity, and regulatory experience keeps North America ahead in deployment speed across the AI in omics market.
Europe remains a major region in the AI in omics market, even as its policy structure both enables longer-term data use and raises near-term compliance costs for many participants. The European Commission states that the EHDS Regulation entered into force in March 2026 and covers secondary use of genomic, proteomic, transcriptomic, metabolomic, and epigenomic data. Germany's genomDE model project had integrated more than 5,000 patients by autumn 2024 and targets 100,000 whole-genome sequences over 5 years. These programs should expand the region's usable data base over time, but the operational burden of the EU AI Act and related governance steps still favors better-established vendors.
Asia-Pacific is projected to grow at 37.4% CAGR, which gives it the fastest regional expansion in the AI in omics market size through 2031 and points to rising momentum in government-backed genomics and digital health programs. That pace reflects efforts across major Asian economies to build local sequencing capacity, strengthen clinical data systems, and reduce dependence on Western ancestry-biased training sets. Japan also shows active translation of language models into genomics, with DBCLS reporting in 2026 that ChatTogoVar outperformed GPT-4o in genomic variant interpretation. South America and the Middle East and Africa remain smaller today, but better healthcare infrastructure and growing startup activity should gradually widen future adoption opportunities.
- 10x Genomics
- Agilent Technologies
- Amazon Web Services
- BGI
- Bruker
- Deep Genomics
- DNAnexus
- DNAstack
- Elucidata
- Roche
- Fabric Genomics
- Illumina
- Lifebit
- NVIDIA
- Oxford Nanopore Technologies
- PacBio
- QIAGEN
- SOPHiA GENETICS
- Tempus AI
- Thermo Fisher Scientific
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 Introduction
- 1.1 Study Assumptions & Market Definition
- 1.2 Scope of the Study
2 Research Methodology
3 Executive Summary
4 Market Landscape
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Precision Medicine Adoption in Oncology and Rare Disease Workflows
- 4.2.2 Rising Omics Data Volumes and Complexity
- 4.2.3 AI-Enabled Target and Biomarker Discovery Acceleration
- 4.2.4 Expansion of Clinical Multiomic Assays and Companion Diagnostics
- 4.2.5 Billion-Cell Atlas Programs Expanding Training Corpora
- 4.2.6 Federated Clinico-Omics Environments Enabling Model Development
- 4.3 Market Restraints
- 4.3.1 Data Privacy, Consent, and Cybersecurity Constraints
- 4.3.2 Multiomics Data Standardization and Interoperability Gaps
- 4.3.3 EU AI Act and EHDS Compliance Burden
- 4.3.4 Atlas-Scale Annotation and Label Quality Bottlenecks
- 4.4 Value Chain Analysis
- 4.5 Regulatory Landscape
- 4.6 Technological Outlook
- 4.7 Porter's Five Forces
- 4.7.1 Bargaining Power of Suppliers
- 4.7.2 Bargaining Power of Buyers
- 4.7.3 Threat of New Entrants
- 4.7.4 Threat of Substitutes
- 4.7.5 Competitive Rivalry
5 Market Size & Growth Forecasts (Value, USD)
- 5.1 By Component
- 5.1.1 Software
- 5.1.2 Hardware
- 5.1.3 Services
- 5.2 By Omics Type
- 5.2.1 Genomics
- 5.2.2 Transcriptomics
- 5.2.3 Proteomics
- 5.2.4 Metabolomics
- 5.2.5 Epigenomics
- 5.3 By AI Technology
- 5.3.1 Machine Learning
- 5.3.2 Deep Learning
- 5.3.3 Natural Language Processing
- 5.3.4 Computer Vision
- 5.3.5 Data Mining
- 5.4 By Application
- 5.4.1 Drug Discovery & Development
- 5.4.2 Clinical Diagnostics
- 5.4.3 Precision Medicine
- 5.4.4 Biomarker Discovery
- 5.4.5 Target Identification & Validation
- 5.5 By End User
- 5.5.1 Pharmaceutical & Biotechnology Companies
- 5.5.2 Academic & Research Institutes
- 5.5.3 Hospitals & Clinical Laboratories
- 5.5.4 Contract Research Organizations
- 5.6 By Geography
- 5.6.1 North America
- 5.6.1.1 United States
- 5.6.1.2 Canada
- 5.6.1.3 Mexico
- 5.6.2 Europe
- 5.6.2.1 Germany
- 5.6.2.2 United Kingdom
- 5.6.2.3 France
- 5.6.2.4 Italy
- 5.6.2.5 Spain
- 5.6.2.6 Rest of Europe
- 5.6.3 Asia-Pacific
- 5.6.3.1 China
- 5.6.3.2 India
- 5.6.3.3 Japan
- 5.6.3.4 South Korea
- 5.6.3.5 Australia
- 5.6.3.6 Rest of Asia-Pacific
- 5.6.4 Middle East and Africa
- 5.6.4.1 GCC
- 5.6.4.2 South Africa
- 5.6.4.3 Rest of Middle East and Africa
- 5.6.5 South America
- 5.6.5.1 Brazil
- 5.6.5.2 Argentina
- 5.6.5.3 Rest of South America
- 5.6.1 North America
6 Competitive Landscape
- 6.1 Market Concentration
- 6.2 Market Share Analysis
- 6.3 Company Profiles (includes Global level Overview, Market level overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share for key companies, Products & Services, and Recent Developments)
- 6.3.1 10x Genomics
- 6.3.2 Agilent Technologies
- 6.3.3 Amazon Web Services
- 6.3.4 BGI Genomics
- 6.3.5 Bruker Corporation
- 6.3.6 Deep Genomics
- 6.3.7 DNAnexus
- 6.3.8 DNAstack
- 6.3.9 Elucidata
- 6.3.10 F. Hoffmann-La Roche AG
- 6.3.11 Fabric Genomics
- 6.3.12 Illumina, Inc.
- 6.3.13 Lifebit
- 6.3.14 NVIDIA
- 6.3.15 Oxford Nanopore Technologies
- 6.3.16 PacBio
- 6.3.17 QIAGEN
- 6.3.18 SOPHiA GENETICS
- 6.3.19 Tempus AI
- 6.3.20 Thermo Fisher Scientific
7 Market Opportunities & Future Outlook
- 7.1 White-space & unmet-need assessment
