
|
시장보고서
상품코드
2073120
오픈 네트워킹 스위치 시장 : 점유율 분석, 업계 동향과 통계, 성장 예측(2026-2031년)Open Networking Switch - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031) |
||||||
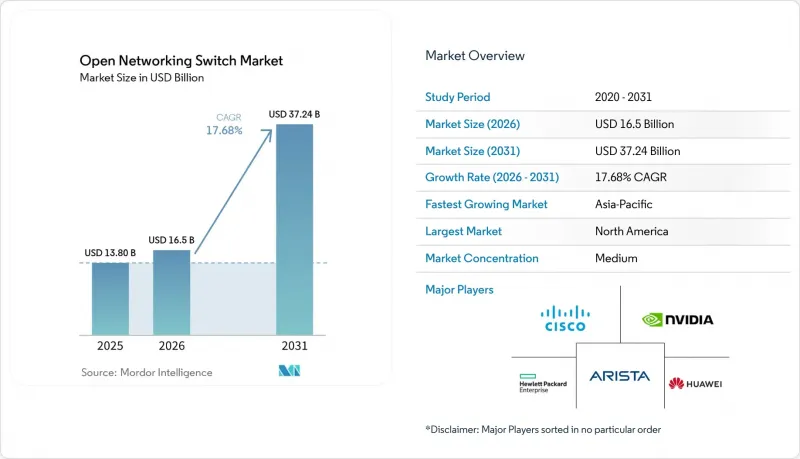
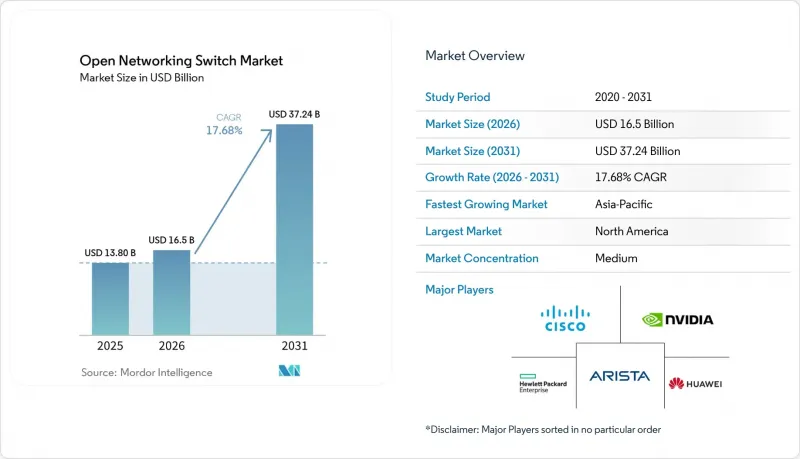
Mordor Intelligence에 의하면, 오픈 네트워킹 스위치 시장 규모는 2025년 138억 달러, 2026년 165억 달러에서 2031년까지 372억 4,000만 달러로 확대한다고 예측되고 있어 2026년부터 2031년까지 연평균 복합 성장률(CAGR)은 17.68%를 나타낼 전망입니다.
본 보고서는 포트 속도(1 GbE 이하, 10-25GbE, 기타), 폼 팩터(고정형 구성, 모듈형 섀시, 기타), 최종 사용자(하이퍼스케일 클라우드 제공업체, 통신 사업자, 기타), 네트워크 운영 체제(자체 개발 상용 NOS, SONiC 기반 NOS, 기타), 지역별로 분류되어 있습니다. 시장 전망은 금액(달러) 기준으로 제시되어 있습니다.
전 세계 오픈 네트워킹 스위치 시장 동향 및 분석
GenAI 클러스터를 위한 하이퍼스케일러의 인프라 확장
생성형 AI의 훈련 워크로드는 데이터센터의 네트워크 설계를 혁신하고 있으며, 지연 시간의 병목 현상 없이 GPU 간 전대전(all-to-all) 통신을 지원하는 스위치에 대한 수요를 높이고 있습니다. 2025년의 대규모 도입에서는 수십만 대의 AI 가속기가 사용되었으며, 16,000노드를 초과하는 클러스터 간에 1밀리초 미만의 집합적 통신을 유지하기 위해 각 가속기에 듀얼 800 GbE 업링크가 필요했습니다. 이러한 변화로 인해, 높은 Radix 스파인 스위치를 갖춘 비차단형 CLOS 토폴로지가 유리해졌으며, 화이트박스 하드웨어와 분산형 운영 체제를 사용함으로써 보다 효율적으로 스케일아웃이 가능해집니다. 2026년의 병렬 확장에서는 SONiC 기반의 스위치를 통해 상호 연결된 10만 개의 AI 칩으로 규모가 확대되었으며, 하드웨어 업데이트 주기가 단축되었습니다. 그 결과 자본 집약도가 높아지면서 시장 집중화가 가속화되고 있으며, 하이퍼스케일러는 인프라 비용을 상각할 수 있는 반면, 소규모 제공업체들은 이익률 압박과 AI 인프라 사업에서 철수해야 할 가능성에 직면해 있습니다.
400G 및 800G 포트의 도입 급증
100 GbE에서 400 GbE 및 800 GbE 이더넷으로의 전환은 데이터센터 역사상 가장 빠른 포트 속도 업그레이드 주기가 되었으며, 도입 기간을 7년에서 3년 가까이 단축했습니다. IEEE 802.3df-2024 표준에 따라 400 Gbps 및 800 Gbps 계층의 상호 운용성이 확립됨에 따라, 다중 벤더 생태계의 성숙이 가속화되고 있습니다. 새로운 스위치용 실리콘은 단일 어드밴스드 노드 다이 위에 최대 64개의 800 GbE 포트를 통합하고 있으며, 포트당 전력 소비량을 기존 400 GbE 설계의 12와트에서 약 8.5와트로 줄였습니다. 51.2 Tbps의 처리량을 실현하는 병렬 실리콘 플랫폼은 하이퍼스케일러용 벤더의 진출이 제한적인 통신 사업자의 엣지 환경에 도입되는 것을 목표로 하고 있습니다. 800 GbE의 경제적 실현 가능성은 총비용 균형을 달성하기 위해, 광모듈 가격이 2025년의 3,500달러에서 2028년까지 1,500달러 미만으로 하락하느냐에 달려 있습니다.
1.6 T를 초과하는 이더넷 PHY의 전력 밀도 병목 현상
1.6 Tbps 이상의 물리 계층 신호 전송은 기존 공랭식 방식으로는 해결할 수 없는 방열 한계로 인해 제약을 받고 있으며, 이로 인해 시스템의 복잡성과 비용을 증가시키는 아키텍처 변경을 피할 수 없게 되었습니다. 200 Gbps에서 1.6 Tbps를 목표로 개발 중인 신규 규격에 따르면, 전기식 SerDes의 전력 소비량은 비선형적으로 증가하고 있으며, 이미 800 GbE 포트당 약 18와트에 달하고, 광 집적화를 실시하지 않을 경우 1.6 Tbps에서는 35와트를 초과할 것으로 예측됩니다. 액체 냉각식 스위치 시스템의 초기 도입 사례에서는 보드당 1.8kW 이상의 열을 방출할 수 있음이 입증되었으나, 냉각수 인프라가 필요하며 이를 갖춘 데이터센터는 현재 15% 미만에 그치고 있어 단기적인 확장성에는 한계가 있습니다.
코패키지형 광모듈은 전기식 리타이머를 제거함으로써 광모듈의 소비 전력을 70% 가까이 줄여 구조적인 효율 향상을 가져오지만, 제조상의 제약이 여전히 걸림돌로 남아 있습니다. 첨단 포토닉 패키징의 수율은 60% 미만에 그치고 있어, 2028년까지는 플러그인형 광모듈과의 비용 경쟁력을 확보할 수 없습니다. 이러한 병목 현상은 800 GbE 64포트나 1.6 Tbps 32포트와 같은 고밀도 구성이 요구되는 AI 패브릭 스위치에서 가장 심각합니다. 그 결과, 통신 사업자들은 차세대 기술로의 업그레이드를 연기하고, 열 관리 및 생산 수율 개선을 기다리는 동안 400 GbE 플랫폼의 수명을 18-24개월 연장할 가능성이 있습니다.
부문별 분석
2025년, 200-400 GbE 대역은 오픈 네트워킹 스위치 시장의 49.62%를 차지했습니다. 이는 클라우드 네이티브 및 AI 워크로드로 인한 데이터센터 트래픽 증가에 따라, 기존의 100 GbE에서 빠르게 전환되고 있는 추세가 반영된 것입니다. 이 대역은 광 모듈 및 스위칭 실리콘 전반에 걸쳐 비용, 전력 효율, 생태계의 성숙도가 균형 있게 갖춰져 있어, 계속해서 판매량의 주류를 이루고 있습니다. 그러나 800 GbE 이상의 대역폭 시장은 250 ns 미만의 스파인 지연 시간과 고라딕스 비차단 아키텍처가 필요한 GPU 클러스터에 힘입어 연평균 성장률(CAGR) 24.62%로 성장할 것으로 전망됩니다. 대규모 도입 사례를 통해 Radix 64 패브릭이 오버구독으로 인한 성능 저하를 초래하지 않으면서 이스트-웨스트 트래픽을 유지하기 위한 최적의 토폴로지임이 입증되었습니다.
800 GbE 도입에 있어 경제적 전환점은 광 모듈의 비용 추이와 전력 효율 향상과 밀접한 관련이 있습니다. 차세대 스위치 실리콘에 통합된 코패키지형 광모듈 아키텍처를 통해 포트당 전력 소비량이 8.5 W에서 약 5.2 W로 감소하는 동시에, 표준 열 설계 범위 내에서 고밀도의 64포트 800 GbE 구성이 가능해집니다. 이러한 개선을 통해 페이스플레이트의 용량도 확보되어 랙 수준의 처리량 밀도가 향상됩니다. 그러나 이 기술이 널리 보급될지는 2028년까지 광모듈 가격이 1,500달러 아래로 떨어지느냐에 달려 있습니다. 이는 플러그인 방식의 대체 제품과 총 비용 면에서 동등한 수준을 달성하고, 대규모 엔터프라이즈 및 하이퍼스케일 환경에서의 도입 주기를 가능하게 하기 위해 필요한 기준치입니다.
2025년에는 고정형 스위치가 매출의 57.39%를 차지했습니다. 이는 비용 효율성이 뛰어나고 도입이 용이하며, 주류 클라우드 및 엔터프라이즈 워크로드에 적합하다는 점을 반영한 것입니다. 그러나 인프라 요구 사항이 고밀도·저지연 GPU 상호 연결로 전환됨에 따라, AI 패브릭 어플라이언스 시장은 연평균 성장률(CAGR) 22.34%로 확대되고 있습니다. NVLink-over-Ethernet과 같은 새로운 사양에서는 1RU 고정형 시스템의 물리적 및 열적 한계를 뛰어넘는 102.4 Tbps의 Radix 64 스파인 아키텍처가 필요합니다. 초기 1.6 Tbps 수냉식 프로토타입에서는 보드당 약 1.8 kW의 방열 수준이 확인되었으며, 이는 기존 공냉식 모듈형 섀시 설계가 차세대 AI 환경에서 확장성 제약에 직면하게 되는 이유를 여실히 보여주고 있습니다.
디스어그리게이트형 모듈러 분야는 섀시 수준의 유연성과 화이트박스 비용 구조를 결합한 하이브리드 모델로 자리매김하고 있습니다. 고성능 라우팅용 실리콘을 기반으로 하는 이 플랫폼은 최대 14.4 Tbps의 처리량을 실현하며, 15년에 걸친 장기 수명 주기를 가진 인프라를 우선시하는 중견 통신 사업자의 요구를 충족시킵니다. 이러한 접근 방식을 통해 오픈 네트워킹 OS와의 호환성을 유지하면서 슬롯 단위로 단계적인 업그레이드가 가능해집니다. 경쟁이 치열해지고 있음에도 불구하고, AI 패브릭 스위치는 공급업체공급량이 제한적이고 성능 요구 사항이 높기 때문에 당분간 40% 전후의 매출 총이익률을 유지할 것으로 예상되지만, 표준화 노력으로 인해 향후 가격 압박이 커질 가능성이 있습니다.
지역별 분석
북미는 버지니아주, 오리건주, 텍사스주의 주요 데이터센터 허브에 하이퍼스케일러가 집중된 것을 배경으로, 2025년 매출의 41.34%를 차지했습니다. 이 지역은 24개월로 단축된 인프라 교체 주기와 800 GbE의 조기 도입이라는 이점을 누리고 있어, AI 및 클라우드 워크로드를 신속하게 확장할 수 있게 되었습니다. 사업자들은 단기적인 비용 효율성보다 성능과 지연 시간을 우선시하고 있기 때문에 부품 비용 상승에도 불구하고 고밀도 AI 패브릭의 도입이 수요를 뒷받침하고 있습니다. 이러한 동향은 북미의 구조적 리더십을 강화하고 있으며, 하이퍼스케일러들이 기술 전환을 주도하고 벤더들의 로드맵에 영향을 미치며, 전 세계 동종 업계 경쟁사들보다 앞서 차세대 스위칭 아키텍처의 상용화를 가속화하고 있습니다.
아시아태평양은 AI 대응 인프라에 대한 대규모 투자와 하이퍼스케일 확장에 힘입어 2031년까지 연평균 성장률(CAGR) 18.32%를 기록하며 성장할 것으로 전망됩니다. 도입 규모는 SONiC 기반 스위치를 통해 상호 연결된 최대 10만 개의 가속기로 구성된 클러스터로 확대되고 있으며, 이는 디어그리게이트형 네트워크 모델의 도입이 활발해지고 있음을 보여줍니다. 중국과 인도에서 정부가 주도하는 공급망 현지화는 국내 ASIC 개발을 촉진하고, 기존 반도체 공급업체에 대한 의존도를 낮출 가능성이 있습니다. 이러한 지역적 변화는 특히 소버린 클라우드 이니셔티브와 데이터 현지화 요건이 인프라 투자 전략에 지속적으로 영향을 미치고 있는 상황에서 기존 공급업체에 경쟁 압력을 가하는 한편 지역 생태계를 강화하게 될 것입니다.
유럽은 에너지 비용의 급등과 복잡한 규제로 인한 구조적 제약에 직면해 있어, 북미나 아시아태평양에 비해 하이퍼스케일 확장이 제한되고 있습니다. 그러나 5G 전송 네트워크에서 통신 사업자 주도의 도입은 오픈 네트워킹 솔루션에 대한 안정적인 수요를 창출하고 있으며, 기업 시장의 성장 둔화를 부분적으로 상쇄하고 있습니다. 중동 및 아프리카는 여전히 초기 단계 시장이며, 주로 일부 국가에 하이퍼스케일러가 진출함에 따라 성장하고 있지만, 기업 차원의 도입은 제한적입니다. 남미에서는 브라질에서 지역적 성장이 나타나고 있으며, 지연 시간에 민감한 핀테크 워크로드가 고속 스위칭에 대한 수요를 견인하고 있지만, 보다 광범위한 지역적 확장은 거시경제의 안정성과 인프라 투자 능력에 좌우되는 상황입니다.
기타 혜택:
- 엑셀 형식 시장 예측(ME) 시트
- 3개월간의 애널리스트 지원
목차
제1장 서론
제2장 조사 방법
제3장 주요 요약
제4장 시장 구도
제5장 시장 규모와 성장 예측
제6장 경쟁 구도
제7장 시장 기회와 향후 전망
JHSAccording to Mordor Intelligence, the open networking switch market size is projected to expand from USD 13.8 billion in 2025 and USD 16.5 billion in 2026 to USD 37.24 billion by 2031, registering a CAGR of 17.68% between 2026 and 2031.
This report is Segmented by Port Speed (1 GbE and Below, 10 To 25 GbE, and More), Form Factor (Fixed Configuration, Modular Chassis, and More), End-User (Hyperscale Cloud Providers, Telecommunications Operators, and More), Network Operating System (Proprietary Commercial NOS, SONiC-Based NOS, and More), and Geography. The Market Forecasts are Provided in Terms of Value (USD).
Global Open Networking Switch Market Trends and Insights
Hyperscaler Build-outs for GenAI Clusters
Generative AI training workloads are reshaping data center network design, increasing demand for switches that support all-to-all GPU communication without latency bottlenecks. Large-scale deployments in 2025 used hundreds of thousands of AI accelerators, each requiring dual 800 GbE uplinks to sustain sub-millisecond collective communication across clusters with more than 16,000 nodes. This shift favors non-blocking Clos topologies with high-radix spine switches, which scale more efficiently using white-box hardware and disaggregated operating systems. Parallel deployments in 2026 scaled toward 100,000 AI chips interconnected via SONiC-based switches, enabling faster hardware refresh cycles. The resulting capital intensity is driving market concentration, as hyperscalers amortize infrastructure costs, while smaller providers face margin compression or potential exit from AI infrastructure.
Surge in 400G and 800G Port Deployments
The transition from 100 GbE to 400 GbE and 800 GbE Ethernet marks the fastest port-speed upgrade cycle in data center history, compressing adoption timelines from 7 years to nearly 3 years. The IEEE 802.3df-2024 standard established interoperability for 400 Gbps and 800 Gbps layers, accelerating the maturity of the multi-vendor ecosystem. New switch silicon integrates up to 64 800 GbE ports on a single advanced-node die, reducing per-port power consumption to roughly 8.5 watts, down from 12 watts in prior 400 GbE designs. Parallel silicon platforms delivering 51.2 Tbps throughput are targeting telco edge deployments where hyperscaler-focused vendors have limited presence. The economic viability of 800 GbE depends on optics pricing declining from USD 3,500 in 2025 to below USD 1,500 by 2028 to reach total cost parity.
Ethernet PHY Power Density Bottlenecks above 1.6 T
Physical-layer signaling at 1.6 Tbps and beyond is constrained by thermal dissipation limits that conventional air cooling cannot address, forcing architectural changes that increase system complexity and cost. Emerging standards under development for 200 Gbps to 1.6 Tbps reveal that electrical SerDes power consumption scales non-linearly, already reaching about 18 watts per 800 GbE port and projected to exceed 35 watts at 1.6 Tbps without optical integration. Early deployments of liquid-cooled switch systems demonstrate the ability to dissipate over 1.8 kilowatts per board, but require chilled-water infrastructure that is available in fewer than 15% of current data centers, limiting near-term scalability.
Co-packaged optics offer a structural efficiency gain by reducing optical module power consumption by nearly 70% through the elimination of electrical retimers, but manufacturing constraints remain a barrier. Advanced photonics packaging yields are below 60%, preventing cost competitiveness with pluggable optics before 2028. This bottleneck is most acute in AI fabric switches, where high-density configurations such as 64 ports of 800 GbE or 32 ports of 1.6 Tbps are required. As a result, operators may delay next-generation upgrades, extending the lifecycle of 400 GbE platforms by 18 to 24 months while awaiting improvements in thermal management and production yields.
Other drivers and restraints analyzed in the detailed report include:
- Accelerated Adoption of Disaggregated Hardware-Software Architectures
- Open-Source NOS Maturity (SONiC, Open-NOS)
- Fragmented NOS Certification and Support Ecosystem
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
The 200 to 400 GbE tier accounted for 49.62% of the open networking switch market in 2025, reflecting rapid migration from legacy 100 GbE as data center traffic intensified with cloud-native and AI workloads. This band remains the volume anchor due to balanced cost, power efficiency, and ecosystem maturity across optics and switching silicon. However, the 800 GbE and above tier is projected to grow at a 24.62% CAGR, driven by GPU clusters requiring sub-250 ns spine latency and high-radix, non-blocking architectures. Large-scale deployments have validated radix-64 fabrics as the preferred topology for sustaining east-west traffic without oversubscription penalties.
The economic inflection point for 800 GbE adoption is closely linked to the trajectories of optics costs and power-efficiency improvements. Co-packaged optics architectures integrated into next-generation switch silicon reduce per-port power consumption from 8.5 W to approximately 5.2 W, while enabling dense 64-port 800 GbE configurations within standard thermal envelopes. These gains also free faceplate capacity, improving rack-level throughput density. However, widespread adoption depends on optical module pricing declining below USD 1,500 by 2028, a threshold required to achieve total cost parity with pluggable alternatives and unlock large-scale enterprise and hyperscale deployment cycles.
Fixed configuration switches accounted for 57.39% of revenue in 2025, reflecting their cost efficiency, ease of deployment, and suitability for mainstream cloud and enterprise workloads. However, AI fabric appliances are expanding at a 22.34% CAGR as infrastructure requirements shift toward high-density, low-latency GPU interconnects. Emerging specifications such as NVLink-over-Ethernet require 102.4 Tbps radix-64 spine architectures that exceed the physical and thermal limits of 1RU fixed systems. Early 1.6 Tbps liquid-cooled prototypes demonstrate heat dissipation levels near 1.8 kW per board, underscoring why traditional air-cooled modular chassis designs face scaling constraints in next-generation AI environments.
The disaggregated modular segment is positioning itself as a hybrid model, combining chassis-level flexibility with white-box cost structures. Platforms built on advanced routing silicon deliver up to 14.4 Tbps throughput, addressing mid-tier telecom operators that prioritize long lifecycle infrastructure spanning 15 years. This approach enables incremental slot-level upgrades while maintaining compatibility with open networking operating systems. Despite increasing competition, AI fabric switches are expected to sustain gross margins near 40% in the near term due to limited supplier availability and high performance requirements, although standardization initiatives are likely to compress pricing over time.
Complete Report Scope:
- By Port Speed
- 1 GbE and Below
- 10-25 GbE
- 40-100 GbE
- 200-400 GbE
- 800 GbE and Above
- By Form Factor
- Fixed Configuration Switches
- Modular Chassis Switches
- Disaggregated Modular Platforms
- High-Density AI Fabric Switches
- By End-User
- Hyperscale Cloud Providers
- Telecommunications Operators
- Large Enterprises
- Small and Medium Enterprises
- Government and Public Sector
- By Network Operating System
- Proprietary Commercial NOS
- SONiC-based NOS
- Cumulus Linux-based NOS
- P4-Programmable / SDN NOS
- In-house Developed NOS
- By Geography
- North America
- United States
- Canada
- Mexico
- South America
- Brazil
- Argentina
- Rest of South America
- Europe
- United Kingdom
- Germany
- France
- Italy
- Spain
- Russia
- Rest of Europe
- Asia-Pacific
- China
- Japan
- India
- South Korea
- Australia
- Singapore
- Rest of Asia-Pacific
- Middle East
- Saudi Arabia
- United Arab Emirates
- Israel
- Turkey
- Rest of Middle East
- Africa
- South Africa
- Nigeria
- Kenya
- Egypt
- Rest of Africa
- North America
Geography Analysis
North America accounted for 41.34% of 2025 revenue, driven by hyperscaler concentration in major data center hubs across Virginia, Oregon, and Texas. The region benefits from accelerated 24-month infrastructure refresh cycles and early adoption of 800 GbE, enabling rapid scaling of AI and cloud workloads. High-density AI fabric deployments sustain demand despite component cost inflation, as operators prioritize performance and latency over near-term cost efficiency. This dynamic reinforces North America's structural leadership, with hyperscalers dictating technology transitions, influencing vendor roadmaps, and accelerating the commercialization of next-generation switching architectures ahead of global peers.
Asia-Pacific is projected to grow at an 18.32% CAGR through 2031, supported by large-scale investments in AI-ready infrastructure and hyperscale expansion. Deployments are scaling toward clusters of up to 100,000 accelerators interconnected via SONiC-based switches, indicating strong adoption of disaggregated networking models. Government-led supply chain localization in China and India is expected to stimulate domestic ASIC development, potentially reducing dependence on incumbent silicon providers. This regional shift introduces competitive pressure on established suppliers while strengthening local ecosystems, particularly as sovereign cloud initiatives and data localization requirements continue to influence infrastructure investment strategies.
Europe faces structural constraints from elevated energy costs and regulatory complexity, limiting hyperscale expansion relative to North America and Asia-Pacific. However, telecom-driven deployments in 5G transport networks provide stable demand for open networking solutions, partially offsetting enterprise slowdown. The Middle East and Africa remain early-stage markets, primarily driven by hyperscaler entry points in select countries, with limited enterprise adoption. South America shows localized growth in Brazil, where latency-sensitive fintech workloads are driving demand for higher-speed switching, though broader regional expansion remains contingent on macroeconomic stability and infrastructure investment capacity.
- Edgecore Networks Corporation
- Accton Technology Corporation
- Quanta Cloud Technology LLC
- Celestica Inc.
- Delta Electronics, Inc.
- Alpha Networks Inc.
- Super Micro Computer, Inc.
- UfiSpace Co., Ltd.
- Foxconn Interconnect Technology Limited
- Inventec Corporation
- Lanner Electronics Inc.
- Wistron NeWeb Corporation
- Advantech Co., Ltd.
- Flex Ltd.
- Fiberhome Telecommunication Technologies Co., Ltd.
- Ruijie Networks Co., Ltd.
- NoviFlow Inc.
- Netberg Ltd.
- Penguin Computing, Inc.
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Hyperscaler Build-outs for GenAI Clusters
- 4.2.2 Surge in 400G and 800G Port Deployments
- 4.2.3 Accelerated Adoption of Disaggregated Hardware-Software Architectures
- 4.2.4 Open-Source NOS Maturity (SONiC, Open-NOS)
- 4.2.5 Vendor-Neutral Silicon Road-maps Enabling Multi-Vendor Ecosystems
- 4.2.6 Energy-Efficient Chiplets and Liquid-Cooling in Next-Gen Switches
- 4.3 Market Restraints
- 4.3.1 Ethernet PHY Power Density Bottlenecks above 1.6 T
- 4.3.2 Fragmented NOS Certification and Support Ecosystem
- 4.3.3 Supply-Chain Exposure to Single-Vendor ASIC Dominance
- 4.3.4 Security Hardening Gaps in Open Networking Stacks
- 4.4 Industry Value -Chain Analysis
- 4.5 Regulatory Landscape
- 4.6 Technological Outlook
- 4.7 Impact of Macroeconomic Factors on the Market
- 4.8 Porters Five Forces Analysis
- 4.8.1 Bargaining Power of Suppliers
- 4.8.2 Bargaining Power of Buyers
- 4.8.3 Threat of New Entrants
- 4.8.4 Threat of Substitutes
- 4.8.5 Intensity of Competitive Rivalry
5 MARKET SIZE AND GROWTH FORECASTS (VALUE)
- 5.1 By Port Speed
- 5.1.1 1 GbE and Below
- 5.1.2 10-25 GbE
- 5.1.3 40-100 GbE
- 5.1.4 200-400 GbE
- 5.1.5 800 GbE and Above
- 5.2 By Form Factor
- 5.2.1 Fixed Configuration Switches
- 5.2.2 Modular Chassis Switches
- 5.2.3 Disaggregated Modular Platforms
- 5.2.4 High-Density AI Fabric Switches
- 5.3 By End-User
- 5.3.1 Hyperscale Cloud Providers
- 5.3.2 Telecommunications Operators
- 5.3.3 Large Enterprises
- 5.3.4 Small and Medium Enterprises
- 5.3.5 Government and Public Sector
- 5.4 By Network Operating System
- 5.4.1 Proprietary Commercial NOS
- 5.4.2 SONiC-based NOS
- 5.4.3 Cumulus Linux-based NOS
- 5.4.4 P4-Programmable / SDN NOS
- 5.4.5 In-house Developed NOS
- 5.5 By Geography
- 5.5.1 North America
- 5.5.1.1 United States
- 5.5.1.2 Canada
- 5.5.1.3 Mexico
- 5.5.2 South America
- 5.5.2.1 Brazil
- 5.5.2.2 Argentina
- 5.5.2.3 Rest of South America
- 5.5.3 Europe
- 5.5.3.1 United Kingdom
- 5.5.3.2 Germany
- 5.5.3.3 France
- 5.5.3.4 Italy
- 5.5.3.5 Spain
- 5.5.3.6 Russia
- 5.5.3.7 Rest of Europe
- 5.5.4 Asia-Pacific
- 5.5.4.1 China
- 5.5.4.2 Japan
- 5.5.4.3 India
- 5.5.4.4 South Korea
- 5.5.4.5 Australia
- 5.5.4.6 Singapore
- 5.5.4.7 Rest of Asia-Pacific
- 5.5.5 Middle East
- 5.5.5.1 Saudi Arabia
- 5.5.5.2 United Arab Emirates
- 5.5.5.3 Israel
- 5.5.5.4 Turkey
- 5.5.5.5 Rest of Middle East
- 5.5.6 Africa
- 5.5.6.1 South Africa
- 5.5.6.2 Nigeria
- 5.5.6.3 Kenya
- 5.5.6.4 Egypt
- 5.5.6.5 Rest of Africa
- 5.5.1 North America
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Strategic Moves
- 6.3 Market Share Analysis
- 6.4 Company Profiles (includes Global Level Overview, Market Level Overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share, Products and Services, Recent Developments)
- 6.4.1 Edgecore Networks Corporation
- 6.4.2 Accton Technology Corporation
- 6.4.3 Quanta Cloud Technology LLC
- 6.4.4 Celestica Inc.
- 6.4.5 Delta Electronics, Inc.
- 6.4.6 Alpha Networks Inc.
- 6.4.7 Super Micro Computer, Inc.
- 6.4.8 UfiSpace Co., Ltd.
- 6.4.9 Foxconn Interconnect Technology Limited
- 6.4.10 Inventec Corporation
- 6.4.11 Lanner Electronics Inc.
- 6.4.12 Wistron NeWeb Corporation
- 6.4.13 Advantech Co., Ltd.
- 6.4.14 Flex Ltd.
- 6.4.15 Fiberhome Telecommunication Technologies Co., Ltd.
- 6.4.16 Ruijie Networks Co., Ltd.
- 6.4.17 NoviFlow Inc.
- 6.4.18 Netberg Ltd.
- 6.4.19 Penguin Computing, Inc.
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment
